새소식
반응형
https://openai.com/research/video-generation-models-as-world-simulators?utm_source=pytorchkr
Video generation models as world simulators
We explore large-scale training of generative models on video data. Specifically, we train text-conditional diffusion models jointly on videos and images of variable durations, resolutions and aspect ratios. We leverage a transformer architecture that oper
openai.com
Video generation models as world simulators.
텍스트-비디오 AI 모델로 텍스트 지시가 주어지면 1분 분량의 고화질 비디오를 생성할 수 있다. 여러 캐릭터, 다양한 동작, 그리고 배경이 포함된 복잡한 장면을 생성할 수 있고 스타일을 일관되게 유지하면서 동영상 내에서 여러 장면을 생성할 수 있다.
가능한 기능 :
인풋 이미지:

인풋 프롬프트:
A Shiba Inu dog wearing a beret and black turtleneck.
결과물:

참고 : https://arca.live/b/airecent/99124151?p=1
✅ 생각보다 모션이 자연스럽고 이동할 때 바뀌는 배경과 오브젝트들도 잘 연결된다. 한 번 사용해보고 싶다!
https://ai.google.dev/gemma?utm_source=pytorchkr&hl=ko
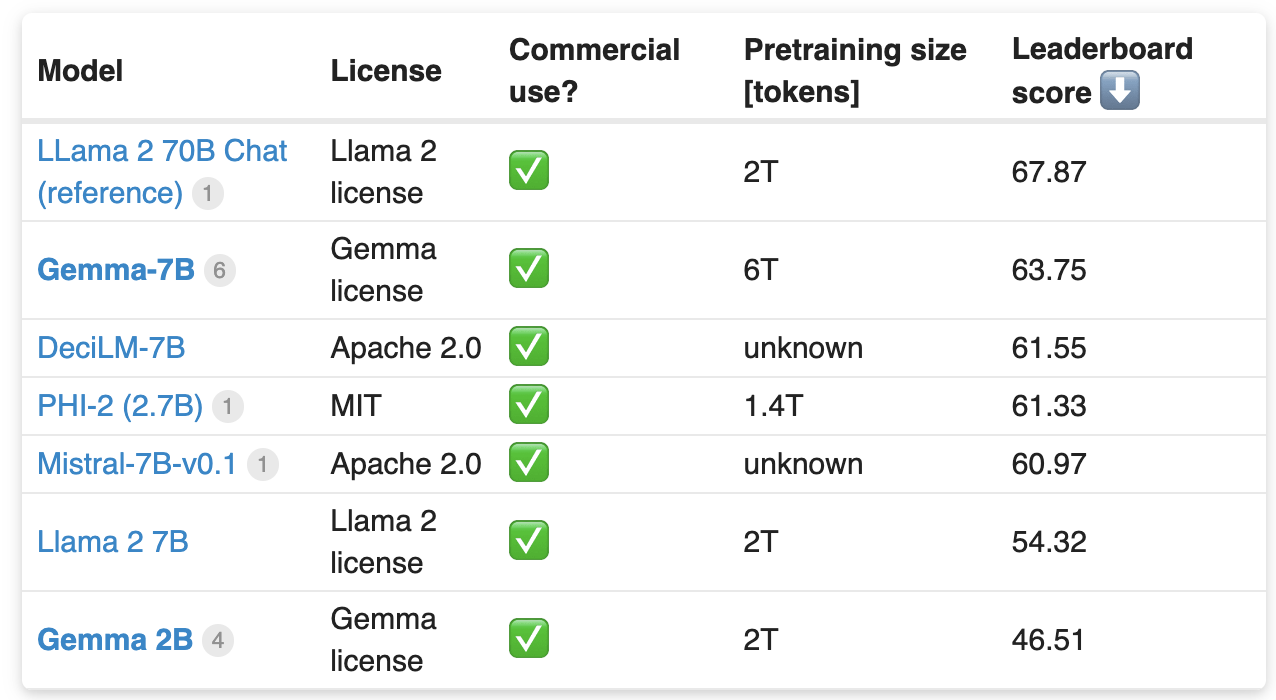
Phi와 같은 2B 규모의 경량화된 LLM들의 반열에 참여하며 Gemma 2B과 7B 모델을 Gemma License로 공개했다. Gemini 모델을 만드는 데 사용된 연구와 기술을 바탕으로 경량화된 모델을 소개했는데, 비슷한 크기의 다른 오픈 모델들보다 성능이 뛰어나다.
GPU, NPU에 이어 LPU(Language Processing Unit) AI 칩이 등장했다. 이 장치를 사용해 대규모 언어 모델 추론 벤치마크에서 18배 가량 빠른 성능을 보여줬다.

Groq의 시스템은 다른 추론 서비스의 최대 4배에 달하는 처리량을 달성하면서 Mistral 자체 서비스의 1/3 미만의 가격을 청구한다고 보고됐다. 게다가 Groq의 칩은 전적으로 미국에서 제조되고 있어 NVIDA, AMD가 대만과 한국에 의존하는 것과 대조된다.
그러나 현재 가격이 과연 지속 가능한지 홍보를 위한 전략인지에 대해서는 의견이 분분하다.
✅ 과연 얼만큼 경쟁력이 있을지 더 알아보고 싶다.
게다가 LLM에 대한 질의 품질을 획기적으로 높이는 Self-Discover 라는 프레임워크를 구글 딥마인드에서 발표했다. 핵심 아이디어는 LLM(Large Language Models)이 복잡한 추론 문제를 해결하기 위해 작업 내재적 추론 구조를 셀프 디스커버리할 수 있도록 하는 것이다. 이는 일반적인 프롬프트 방법에서는 어려운데, LLM이 비판적 사고와 단계별 사고와 같은 여러 원자 추론 모듈들(Atomic Reasoning Modules)을 선택하여 디코딩 시 LLM이 따라야 할 명시적 추론 구조로 구성하는 자체 발견 과정을 포함하고 있다. Self-Discover는 BigBench-Hard, 근거 에이전트 추론(Grounded Agent Reasoning) 및 MATH1과 같은 까다로운 추론 벤치마크에서 GPT-4 및 PaLM2와 같은 모델의 성능이 크게 향상되었음을 보여줬다.
✅ Self-Discover 기술은 Prompt engineering을 의미가 없는 것으로 만들 가능성이 높다고 한다. 관련 논문을 찾아봐야겠다.
BASE TTS는 현재까지 가장 큰 TTS 모델로, 10만 시간의 공개 도메인 음성 데이터로 훈련됐다. 데이터 크기와 모델 파라미터 수를 보면 아주 자연스러운 음성 출력이 가능할 것 같다.
소중한 공감 감사합니다