언어 모델 사이즈를 키운다고 결과(사용자 의도에 맞는 출력)가 좋아지는 것은 아니다. Making language models bigger does not inherently make them better at following a user’s intent.
LLM’s unintended behaviors 의 이유는 대부분의 언어 모델링의 목표가 “다음 토큰 예측”이지 “사용자 명령에 잘 따르기”가 아니기 때문이다. 이를 misaligned 라고 표현한다.
unintended behaviors : making up facts, generating biased or toxic text, or simply not following user instructions
연구 내용
언어모델 aligning을 통해 helpful, honest, harmless 한 언어모델을 만든다.
helpful : 프롬프트의 의도를 추론하고 지시를 따라야 한다.
honest : 모델의 기술이 사실이어야 한다. (truthfulness)
harmless : 보호 계층을 폄하하는 내용, 성적 내용 또는 폭력적인 내용을 포함하지 않아야 한다.
RLHF. 사람의 선호도를 ‘Reward’로 사용한 강화학습으로 언어모델을 fine-tuning 한다.
데이터 수집
[ 프롬프트 ]
openAI API에 제출된 프롬프트 수집
민감 정보(개인 식별 정보) 필터링 진행
labeler가 프롬프트 작성
instructGPT 초기 모델 학습을 위해 Plain, Few-shot, User-based 3가지 유형의 프롬프트를 제작
위 프롬프트들로 SFT dataset, RM dataset, PPO dataset 3가지 데이터셋 제작
[ 프롬프트 답변 ]
labler가 답변 작성
여러 모델들의 outputs
프롬프트 답변들에 대한 랭킹 매기기
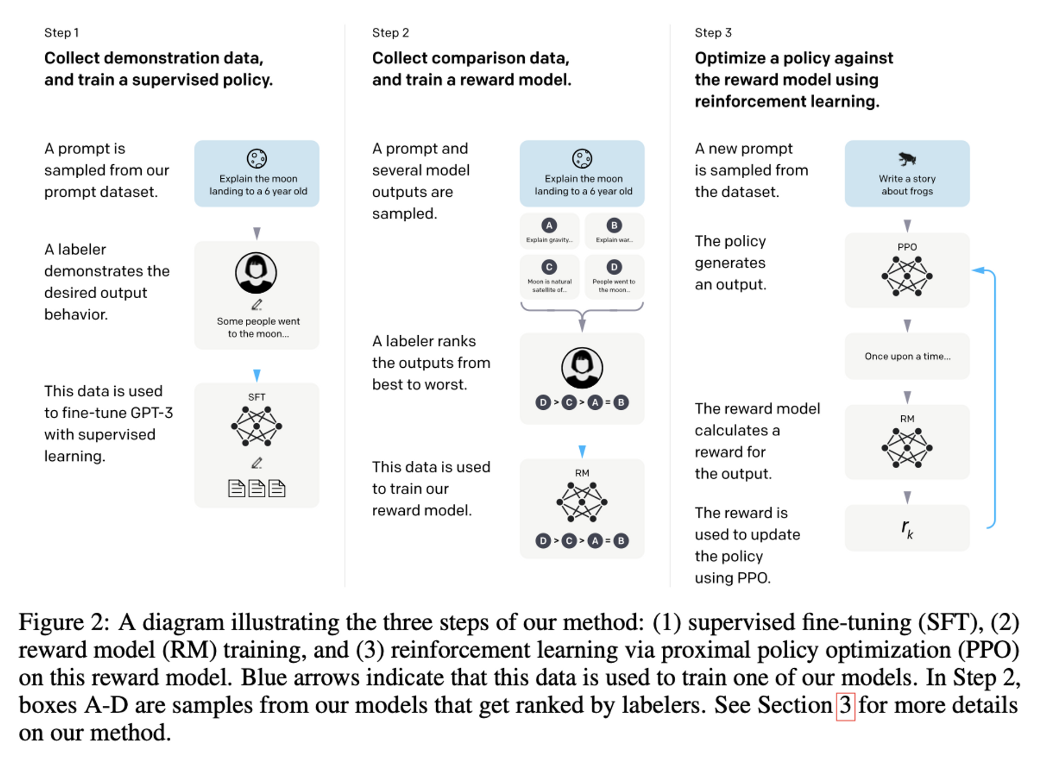
RLHF (Reinforcement Learning from Human Feedback)
사람의 선호도를 ‘Reward’로 사용한 강화학습 방법
[ instructGPT 학습 방법 ]
Supervised fine-tuning (SFT) GPT-3를 labeler가 작성한 답변으로 fine-tuning 한 모델
Reward Modeling (RM) 어떤 텍스트 프롬프트에 대한 LLM의 응답(respose)에 대한 reward scalar 값을 예측하는 모델. 하나의 프롬프트 input에 대한 여러 모델의 output 값들의 ranking point 데이터셋으로 학습한다. 이때 ranking을 인간이 직접 매기기 때문에 Human Feeback이라고 한다.
Reinforcement learning (RL) RM을 reward function으로 사용하고, PPO 알고리즘으로 보상을 최대화 하도록 LLM을 fine-tuning.
기존의 pretrained된 Model (frozen) 과 fine-tuning을 진행 할 model (Trainable) 을 준비하고, 각각에 text-prompt를 넣는다.
final reward score 계산
각각의 LLM에서 나온 outputs 사이의 KL-Divergence 를 계산
Fine-tuning을 진행 할 LLM에서 나온 output을 Reward Model에 넣어서 reward score 얻는다.