새소식
반응형
이진탐색이란, 매 탐색마다 탐색 범위를 반으로 좁혀가며 빠르게 탐색하는 알고리즘이다.
이진탐색을 수행하기 위해서는 리스트(배열)가 정렬되어 있어야 한다.
크기가 N인 list에서 target이라는 특정 데이터를 찾아내고 싶다고 가정하자.
(left와 right는 list의 인덱스를 의미한다.)
left = 0, right = n - 1로 초기화한다.mid = (left + right) // 2로 설정한다.list[mid] == target이라면 탐색을 종료한다.list[mid] != target이라면,
list[mid] > target : right = mid - 1로 갱신하고 2번으로 돌아간다.list[mid] < target : left = mid + 1로 갱신하고 2번으로 돌아간다.🔺 mid를 설정할 때 left + (right - left) // 2로 설정하기도 한다. (오버플로우를 피하기 위해)
이를 그림으로 살펴보자. 아래에서 15라는 데이터를 찾고자 한다.

left와 right로 mid를 설정하자.
중간값이 15보다 작으므로, left를 갱신해야 한다.

left를 갱신하고 mid를 새로 설정했다.
이번에는 중간값이 15보다 크므로, right를 갱신해야 한다.
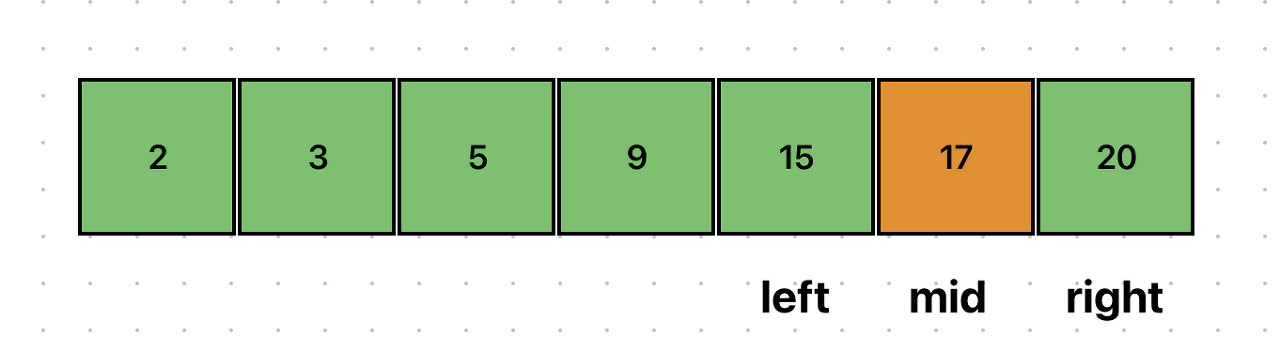
원하는 데이터 15를 찾았다.
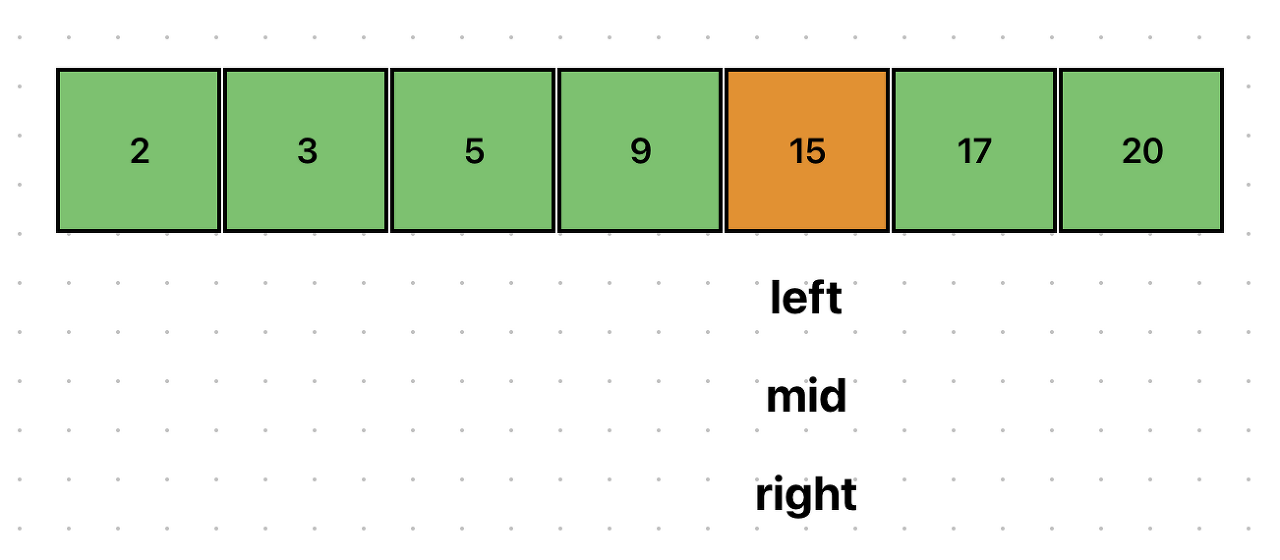
이진탐색은 한번 탐색을 수행할 때 마다, 탐색의 범위가 반으로 줄어든다. 따라서, 시간복잡도는 $O(logN)$이다.
# 재귀
def binary_search(list, target, left, right):
if left > right:
return None
mid = left + (right - left) // 2
# 찾은 경우 중간점 인덱스 변환
if list[mid] == target:
return mid
# 중간점의 값보다 찾고자 하는 값이 작은 경우 왼쪽 확인
elif list[mid] > target:
return binary_search(list, target, left, mid-1)
# 중간점의 값보다 찾고자 하는 값이 큰 경우 오른쪽 확인
else:
return binary_search(list, target, mid+1, right)# 반복문
def binary_search(list, target, left, right):
while left <= right:
mid = left + (right - left) // 2
if list[mid] == target:
return mid
elif list[mid] > target:
right = mid - 1
else:
left = mid + 1
return None최대공약수는 GCD, 최소공배수는 LCM 이라고도 불리며 손코딩으로 많이 출제되는 유형이다.
최대공약수는 유클리드 호제법을 사용해서 구현할 수 있고, 최소 공배수는 최대공약수 알고리즘을 사용하여 구현할 수 있다.
👆 유클리드 호제법이란?
2개의 자연수 $a$,$b$에 대해서 $a$를 $b$로 나눈 나머지를 $r$이라고 할 때 (단, $a > b$), $a$와 $b$의 최대공약수는 $b$와 $r$의 최대공약수와 같다.
이 성질에 따라, $b$를 $r$로 나눈 나머지 $r0$를 구하고 $r$을 $r0$으로 나눈 나머지를 구하는 과정을 반복하여 나머지가 0이 되었을 때 나누는 수가 $a$와 $b$의 최대공약수이다.
수식으로 표현하면 다음과 같다.
$GCD(A, B) = GCD(B, A % B)$
$if A%B = 0 → GCD = B$
$else \ \ GCD(B, A%B)$
def gcd(a, b):
while b > 0:
a, b = b, a % b
return a최소공배수란, 서로 다른 수 $a$, $b$의 배수 중에서 공통되는 배수 중에 가장 작은 값을 의미한다.
$a$와 $b$의 최소공배수는 $a$와 $b$의 곱을 $a$와 $b$의 최대 공약수로 나누면 된다.
def lcm(a, b):
return a * b / gcd(a, b)에라토스테네스의 진행방식은 다음과 같다.
a = [False, False] + [True] * (n-1)
primes=[]
def eratosthenes():
for i in range(2,n+1):
if a[i]:
for j in range(2*i, n+1, i):
a[j] = False
하나의 숫자가 소수인지 아닌지 판별하는 방법으로, 해당 숫자의 제곱근까지 나누어 확인한다.
def is_Prime(number):
if number == 1:
return False
for i in range(2, int(number**0.5)+1):
if number % i == 0:
return False
return True
| 반복문 | 재귀함수 | |
|---|---|---|
| 동작 | 명령을 반복적으로 실행 | 함수 자체를 호출 |
| 체제 | 초기화, 조건, 루프 내 명령문 실행과 제어 변수 업데이트 포함 | 종료 조건(기저조건, Basis)를 지정(조건이 추가될 수 있음) |
| 종료시점 | 설정한 조건에 도달 할 때까지 반복 실행 | 함수 호출 본문에 조건부가 포함, 재귀를 호출하지 않고 함수를 강제 반환 |
| 조건 | 제어 조건이 참이라면 무한 반복 발생 | 조건에 수렴하지 않을 경우 무한 재귀 발생 |
| 무한 반복 | 무한 루프는 CPU 사이클을 반복적으로 사용 | 무한 재귀는 스택 오버플로우 발생 |
| 스택 메모리 | 스택 메모리를 사용하지 않음 | 함수가 호출 될 때마다 새 로컬 변수와 매개 변수 집합, 함수 호출 위치를 저장하는데 사용 |
| 속도 | 빠른 실행 | 느린 실행 |
| 가독성 | 코드 길이가 길어지고 변수가 많아져 가독성이 떨어짐 | 코드 길이와 변수가 적어 가독성이 높아짐 |
재귀함수는 변수를 줄이고 코드 가독성을 높일 수 있지만 stack이라는 메모리 공간을 사용하기 때문에 메모리 제한에 걸릴 수 있다.
DP와 분할정복 모두 문제를 잘게 나누어서, 가장 작은 단위로 분할하여 문제를 해결해 나간다.
그리디(a.k.a 탐욕법) 알고리즘이란, 각 단계에서 가장 최선의 선택을 하는 알고리즘이다. 즉, 현재 상황에서 가장 좋은 결과를 선택해 나가는 방식이고 최적해를 구하는 데에 사용되는 근사적인 방법이다.
따라서 순간마다 하는 선택이 지역적으로도 최적이면서 최종적(전역적)으로도 최적이라는 보장이 있을 때만 사용할 수 있다.
코딩테스트 문제에서 ‘가장 큰 순서대로’, ‘가장 작은 순서대로’와 같은 기준을 알게 모르게 제시해준다.
백트래킹(Backtracking)이란, 해를 찾는 도중 해가 아니어서 막히게되면 그 경로를 더 이상 탐색하지 않고, 되돌아가서 다시 해를 찾아가는 기법이다. 즉, 모든 가능한 경우의 수 중에서 특정 조건을 만족하는 경우만 살펴보는 것으로 효율성을 높이는 탐색 방법이다.
Huffman 코딩이란, 데이터 압축을 수행하는 알고리즘으로, 그리디 알고리즘에 속한다.
| 알고리즘 면접 대비 질문 리스트업 (3) | 2023.06.03 |
|---|---|
| 자료구조 면접 대비 질문 리스트업 (0) | 2023.06.03 |
| 정렬 알고리즘 (0) | 2023.06.02 |
| 해시 테이블 (0) | 2023.06.01 |
| 그래프 / 그래프 탐색 (1) | 2023.05.28 |
소중한 공감 감사합니다